准备工作
网上包括官网讲的都遮遮掩掩的。还是得靠自己,研究了一阵子,做个笔记。
用pycharm调试scrapy
网上大部分教程说的都是新建一个py文件,py里写cmdline.execute("scrapy crawl spider".split())类似语句。这样也可以,但还是得新建个py文件,每次调试时必须从这个文件启动调试,不方便,而且也不利于git。
我用pycharm自带的模块调用法,更方便。
第一步,先在pycharm里打开项目,点击菜单-运行-编辑配置,选择+号新建python配置。
名称:不填的话,pycharm会自动填模块名,也可以自己填一个。记住这个名字。
模块名称:固定写 scrapy.cmdline
参数:crawl固定,debug是你的蜘蛛name,--nolog是不显示scrapy调试信息,可有可无
解释器:选择你装了scrapy的,你希望用的虚拟环境解释器
工作目录:选择scrapy项目的目录,也就是里面有scrapy.cfg文件的那个目录
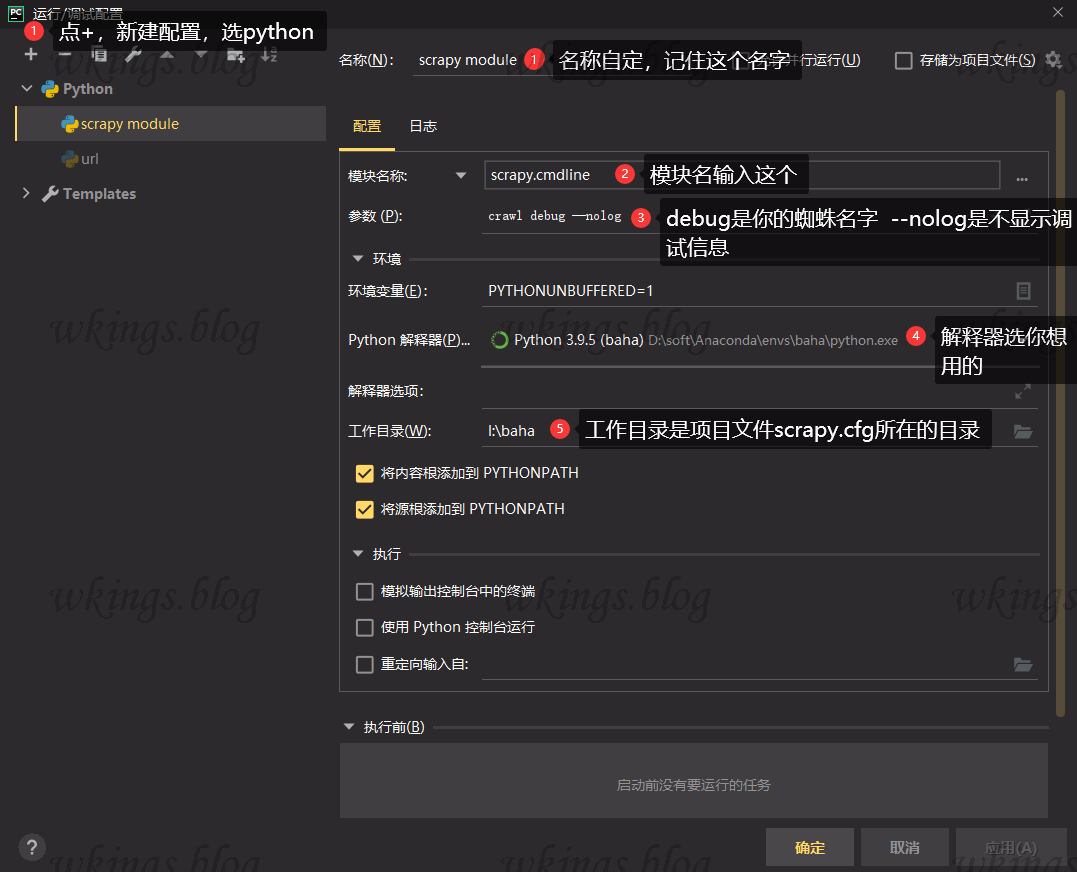
第二步,pycharm里打开你想要调试的scrapy文件,右上角调试环境下拉列表里,选择上一步新建的名称,也就是刚刚建立的调试环境。然后点右边的小蜘蛛按钮,或者按SHIFT+F9,或运行菜单-顶部第二个调试选择,就开始正常调试过程。只要是这个scrapy项目里的py文件,都直接点小蜘蛛即可调试。想要更换蜘蛛,就把调试环境里的debug改一下就行。
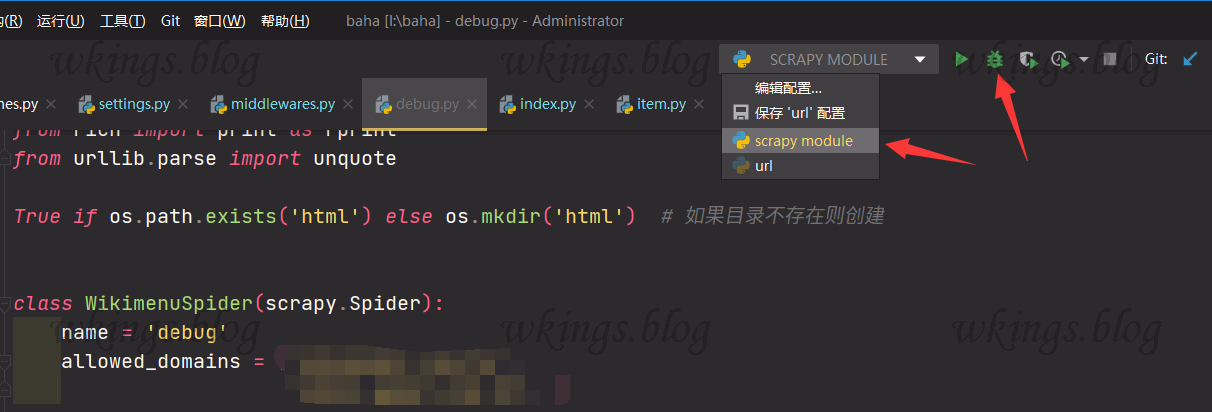
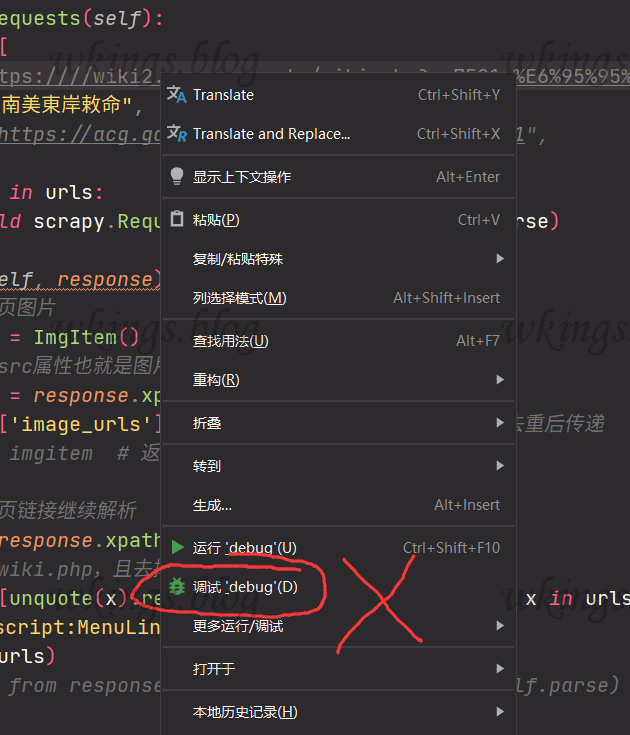
不能选择右键菜单里的调试,那个调试会自动新建一个针对这个文件的调试环境,对普通py文件可以,对scrapy无效。
代码性能比较
response.xpath和beautifulsoup性能比较
解析网页提取链接时有response.xpath和beautifulsoup.find_all()两种选择,通过性能测试,response.xpath速度略快。
1 2 3 4 5 6 7 8 | bs = BeautifulSoup(response.body, 'lxml') for i in range(10000): bs.find_all('a', href=True) # 用时104秒。且每个网页BeautifulSoup都需要实例化 for i in range(10000): response.xpath('//a/@href').getall() # 用时37秒。response是scrapy自带,无需额外操作 |
BeautifulSoup.find_all()方法测试
使用BeautifulSoup的find_all()方法选取HTML网页内容标签时,find_all()可以传入单独标签或标签列表。经过测试,两者性能差别不大,但是单独标签在编写的时候更直观,好修改。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | bs = BeautifulSoup(file_obj, 'lxml') start = time.time() for i in range(1000): bs.find_all('a', href=True) bs.find_all('img', src=True) bs.find_all('link', href=True) bs.find_all('script') print(f"time:{time.time() - start}") # time:161.9159119129181 start = time.time() for i in range(1000): bs.find_all(['a', 'img', 'link', 'script']) print(f"time:{time.time() - start}") # time:137.75350737571716 |
使用列表形式的find_all()时,可以通过find_all()方法的name属性确定具体是哪一个标签。
1 2 3 4 5 6 7 8 9 10 11 12 | tags = bs.find_all(['a', 'img', 'link', 'script']) for tag in tags: # 每个tag都有自己的名字,通过 .name 来获取 # https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/#name if tag.name == 'a': pass elif tag.name == 'img': pass elif tag.name == 'link': pass elif tag.name == 'script': pass |
BeautifulSoup的select_one()方法和find()方法性能比较
使用BeautifulSoup选取唯一的标签时,有select_one()方法和find()方法两种实现方法。经过测试对比,find()比select_one()快一倍。
1 2 3 4 5 6 7 8 9 10 11 12 13 | bs = BeautifulSoup(file_obj, 'lxml') start = time.time() for i in range(10000): bs.select_one('div[id="abc"]') print(f"\n{time.time() - start}") # 9.24462080001831秒 start = time.time() for i in range(10000): bs.find('div', id='abc') print(f"\n{time.time() - start}") # 5.53403115272522秒 |
python使用多进程加快处理速度
这里说的是多进程,而不是多线程。由于GIL锁的存在,在windows下python的多线程除了让代码变的复杂之外毫无作用。而多进程就不同了,只要你CPU够强大,开多少个处理进程都可以,而且开的进程越多,缩短的时间越多。理论上有个公式:N个进程运行时间=1个进程的时间 / N。比如正常运行一个py脚本需要10分钟,那么开2进程需要10/2=5分钟,开4进程需要10/4=2.5分钟。但多进程的缺点是各个进程之间无法通信,数据不共享,除非你额外编一个调度通信程序,不过每个进程运行完之后,结果是可以返回汇总的。
简单的多进程不难,代码模型如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | import os from multiprocessing import Pool, RLock, freeze_support from tqdm import tqdm def 多进程处理函数(list): pass return data # 你要返回的数据,数据类型任意,会存在pool_result里 if __name__ == '__main__': 要处理的列表 = [] # 多进程 # print('Parent process %s' % os.getpid()) t_num = os.cpu_count() - 2 # 进程数 读取CPU逻辑处理器个数 freeze_support() # for Windows support tqdm.set_lock(RLock()) # for managing output contention p = Pool(processes=t_num, initializer=tqdm.set_lock, initargs=(tqdm.get_lock(),)) pool_result = [] # 存放pool池的返回对象列表 for i in range(0, t_num): div = int(len(要处理的列表) / t_num) mod = len(要处理的列表) % t_num if i + 1 != t_num: # print(i, i * div, (i + 1) * div) pool_result.append(p.apply_async(多进程处理函数, args=(要处理的列表[i * div:(i + 1) * div], i))) else: # print(i, i * div, (i + 1) * div + mod) pool_result.append( p.apply_async(多进程处理函数, args=(要处理的列表[i * div:(i + 1) * div + mod], i))) # print('Waiting for all subprocesses done...') p.close() p.join() # 读取pool的返回对象列表。i.get()是读取方法 for i in pool_result: i.get() |
使用了第三方库tqdm进度条,以便直观观看各进程进度。各进程处理后的结果会返回给pool_result列表。重点:进程流程控制代码段必须放在if name == 'main':里,每个进程的代码必须用函数或类包装,放在if name == 'main':外。这是死规定,跟windows底层有关。
下载图片
坑1 图片不下载
【这TM也太坑了】conda全新虚拟环境,安装最新scrapy(2.6.1),代码都对,无论怎么调试但图片就是不下载。原因是scrapy默认没安装下载图片所需的Pillow库。手动conda install Pillow即可。
坑2 gif图片下载后透明度、动态效果消失
scrapy代码是jpeg格式下载,即使你传递给scrapy的图片URL是gif图片,下载回来也变成了jpg格式的gif图片,透明度、动态效果都不见了。
需要重写ImagesPipeline图片管道,增强image_downloaded方法。因此,如果需要gif图片,只能使用自定义图片管道,不能用默认图片管道。如何建立自定义图片管道下面章节有介绍。
参考 https://zhuanlan.zhihu.com/p/81611461 重写ImagesPipeline图片管道,我将他的代码几个函数组合在一起了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | import os from scrapy.utils.misc import md5sum class GvoImgPipeline(ImagesPipeline): # scrapy默认图片是jpeg格式下载,根据https://zhuanlan.zhihu.com/p/81611461 重写下载方法 def image_downloaded(self, response, request, info): try: checksum = None for path, image, buf in self.get_images(response, request, info): if checksum is None: buf.seek(0) checksum = md5sum(buf) width, height = image.size if image.format is None: # 是gif格式 absolute_path = self.store._get_filesystem_path(path) self.store._mkdir(os.path.dirname(absolute_path), info) f = open(absolute_path, 'wb') # use 'b' to write binary data. f.write(response.body) else: self.store.persist_file( path, buf, info, meta={'width': width, 'height': height}, headers={'Content-Type': 'image/jpeg'}) return checksum except: pass |
使用scrapy默认图片管道下载图片
使用scrapy自带的ImagesPipeline管道。自己只需要在items.py里添加一个Item类,在你的蜘蛛spider parse方法里添加处理图片URL代码,在setting.py开启ImagesPipeline管道即可。不需要自己添加pipline管道。
items.py
添加一个Item类,内容固定,类名随意。
1 2 3 4 5 6 7 | class ImgItem(scrapy.Item): # 存放url的下载地址 image_urls = scrapy.Field() # # 图片下载路径、url和校验码等信息(图片全部下载完成后将信息保存在images中) images = scrapy.Field() # # 图片的本地保存地址 # image_paths = scrapy.Field() |
image_urls、images变量名不能修改,否则scrapy无法识别图片信息。如果非要想修改,需要在settings.py里添加设置参数
1 2 3 4 | # # 该字段的值为XxxItem中定义的存储图片链接的image_urls字段 # IMAGES_URLS_FIELD = 'image_urls' # # 该字段的值为XxxItem中定义的存储图片信息的images字段 # IMAGES_RESULT_FIELD = 'images' |
你的蜘蛛文件
你的spider里,parse方法里添加图片URL解析语句,并最终传递给imgitem['image_urls']。传递的值必须是列表,这样才能用yield迭代。如果parse方法之前已经有yield response解析URL,也不影响。scrapy会先处理下载图片,然后再处理网页链接。
处理图片代码的核心思路就是先实例化ImgItem(),再把图片URL下载链接传递给imgitem['image_urls'],最后返回yield实例即可。scrapy内部检测到imgitem['image_urls']就会自动调用下载器去下载图片。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from ..items import ImgItem from bs4 import BeautifulSoup def parse(self, response): # 新添加的 提取图片 imgitem = ImgItem() imglist = [] bs = BeautifulSoup(response.body, 'lxml') for img in bs.select('img'): if 'src' in img.attrs: imglist.append(img.attrs['src']) imgitem['image_urls'] = list(set(imglist)) # 列表去重后传递 yield imgitem # 返回item先交给ImagesPipeline下载图片 # 之前的代码,提取本页链接继续解析 urls = response.xpath('//a/@href').getall() if urls: yield from response.follow_all(urls, callback=self.parse) |
settings.py
添加图片保存位置参数,开启scrapy自带的图片管道。
1 2 3 4 | IMAGES_STORE = './img' ITEM_PIPELINES = { 'scrapy.pipelines.images.ImagesPipeline': 1, } |
图片将会保存在你的项目目录的img文件夹。
ImagesPipeline': 1的意思是这个管道优先级1,最高。
使用自定义管道下载图片
和使用scrapy默认图片管道方法基本一致,除了settings.py不同。参照默认图片管道修改item.py、蜘蛛文件。
使用自定义管道的好处是可以自由定义图片下载流程和设置。比如自定义图片文件名。
piplines.py
新建一个pipline,且继承ImagesPipeline。这里的代码只修改图片保存位置和文件名。其他功能参考https://docs.scrapy.org/en/latest/topics/media-pipeline.html#module-scrapy.pipelines.files
1 2 3 4 5 6 7 8 9 | from urllib.parse import urlparse from scrapy.pipelines.images import ImagesPipeline class GvoImgPipeline(ImagesPipeline): def file_path(self, request, response=None, info=None, *, item=None): # 保存到 settings.py.IMAGES_STORE + urlparse(request.url).path 目录 # urlparse(request.url) = ParseResult(scheme='https', netloc='www.baidu.com', path='/WIKI/61/00016461.JPG', params='', query='', fragment='') # urlparse(request.url).path = '/WIKI/61/00016461.JPG' return urlparse(request.url).path |
settings.py
仍然需要IMAGES_STORE变量,并在ITEM_PIPELINES里加上自定义的管道
1 2 3 4 5 | IMAGES_STORE = './html/img' ITEM_PIPELINES = { 'scrapy.pipelines.images.ImagesPipeline': None, # 关闭默认图片管道 'gvo.pipelines.GvoImgPipeline': 1, # 开启自定义图片管道,优先级为1最高 } |
自定义管道'gvo.pipelines.GvoImgPipeline'中,gvo是项目名,保存在scrapy.cfg,也是保存几个py文件的文件名。.pipelines固定不变,.GvoImgPipeline是piplines.py中自定义的类名。
scrapy设置
scrapy本什么没什么需要设置的。对于爬虫项目的设置,都在项目的settings.py文件里
settings.py
根据你的需要修改。
scrapy默认是深度优先(DFO)爬取,也就是优先获取全站的所有网页,再分析每个网页。这种情况适合网页数量少,抓取网页内容。缺点是如果网页太多,有可能极个别网页无法处理被忽略。如果是爬全站,应该改为广度优先,也就是获取到网页就先处理网页,再进一步爬其他网页。
下载器并发数量设置。CONCURRENT_REQUESTS是总并发数,下面两个分别是针对域名和IP的并发数。总并发数永远大于等于域名/ip并发数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # 广度优先,队列类型为FIFO(first in first out) DEPTH_PRIORITY = 1 SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleFifoDiskQueue' SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.FifoMemoryQueue' # Configure maximum concurrent requests performed by Scrapy (default: 16) # Scrapy 下载器将执行的并发(即同时)请求的最大数量 CONCURRENT_REQUESTS = 1000 # The download delay setting will honor only one of: # CONCURRENT_REQUESTS_PER_DOMAIN = 16 # 将对任何单个域执行的并发(即同时)请求的最大数量 CONCURRENT_REQUESTS_PER_DOMAIN = 20 # CONCURRENT_REQUESTS_PER_IP = 16 # 将对任何单个 IP 执行的并发(即同时)请求的最大数量。 # 如果非零,则忽略CONCURRENT_REQUESTS_PER_DOMAIN,而使用该设置 CONCURRENT_REQUESTS_PER_IP = 0 |

文章评论